

Keep it in a Solution
Naming conventions within the Power Platform are critical. But even the best of us don’t see these things coming. As you explore and apply ALM frameworks to solution design, you’ll start to realise that the only option as a developer or solutions architect is to build inside a solution. That’s where we stumble onto solution publishers.
What are Publishers
Publishers are attributes that become responsible for owning and managing solutions. Say Company A is developing a Power Platform solution and selling it on the Microsoft Marketplace. They will create a publisher called Company A with a prefix that defines the naming convention of the object schemas and names within their solution. For example, their solution has a custom table, and their publisher’s prefix is com. The table schema name will therefore be com_CustomTable.
I recently posted a blog called Master Solution Dependencies Like a Boss. This post discussed best practices for architecting a solution to avoid dependency issues upon deployments. However, the root cause behind this post was based on a recent experience. I needed to deploy a solution, but it had a web of objects that branched into various other solutions. One thing that stood out was how some objects had the publisher’s prefix, while others didn’t. This just got me tangled in the web even more.
A Web of Mystery
When building an app, variable, table, etc. outside of a solution, the environment’s CDS Default Publisher, where applicable, is used to prefix the object. So say I create two tables for a solution I am building. The first table (Test Table 1) is created in Dataverse outside of a solution. The table schema name is now cr993_testtable1. The second table (Test Table 2) is created from within the solution. The solutions publisher is my personal publisher and has the prefix natiturt. Being that the table was now created within the solution, the schema name makes use of the publisher prefix and is therefore called natiturt_testtable2. Let’s add the Test Table 1 object to the solution now by using the Add Existing option. We now have two different prefixed objects that need to live within the same solution. Not a great naming standard, right?
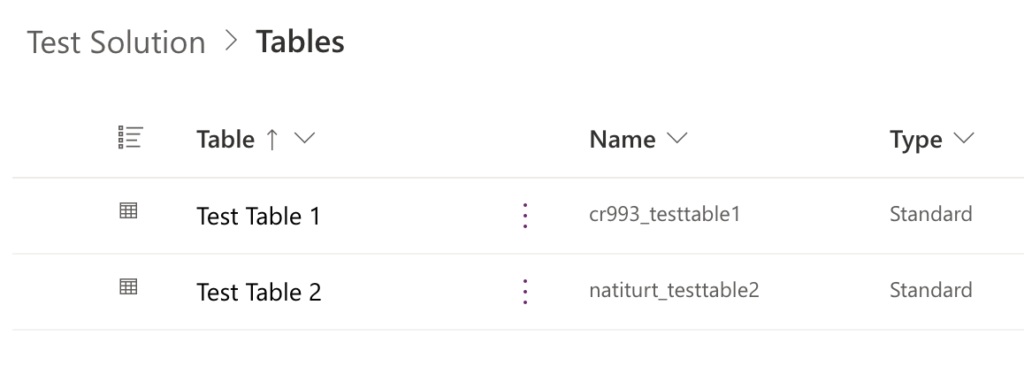
Now let’s spice it up a bit. I’ve created two new Canvas apps. One within the solution and one outside the solution. The app outside the solution is then added to the solution as an external object. Both objects, weirdly enough, have the same prefix, natiturt. Various methods of naming objects are used within the Power Platform. Some objects, such as Power Automate flows, do not even include a prefix in the object name. Others, like environment variables and columns, do.

Down the Rabbit Hole
Things can get even more confusing. Referring back to our two tables we created earlier, let’s go and create some custom columns. Within the solution for our added table, Test Table 1 (cr993_testtable1), we are going to create a new column called Column Prefix. Have a look at how the prefixed schema names no longer match.

Now let’s try doing the same thing for Test Table 2 (natiturt_testtable2) but in reverse. Within Dataverse, outside of the solution, we are going to create a column called Column Prefix. Again, our naming standards for the object schema prefixed names are no longer aligned.

Solution Design
Although not all objects get associated with a prefixed name, I personally find it incredibly frustrating to have a variety of different prefixed objects within my data model, specifically around tables, columns, and relationships. When designing a solution and putting together an ERD and data model, I like my schema to be clean, informative, and structured. Having prefix standards within my data model ensures that when I do need to scale my model, I am fully aware of what lives within my solution and where my dependencies are. It is a very OCD approach to solution design, but I have been down that rabbit hole before, where it becomes a nightmare to locate dependencies based on generic publisher prefixes.
In larger and more complex solutions, I have even found it beneficial to have a variety of publishers across dependent solutions. Consider a segmented solution approach. I’d have a core publisher for the core solution and a publisher per segmented solution. This has personally helped me reinforce my data model as well as maintain sustainable solution dependencies.
Conclusion
In conclusion, solution prefixes are incredibly important when it comes to ownership over solution objects and managing a sustainable Application Lifecycle Management framework. My question is, where do solution architects draw the line between OCD and quality?





Agree 100 % – don’t know what is worse – cr9999_ or new_ Both are horrid – and as for the name powerapps gives a relationship – let’s not go there
Agreed, let’s not go down there today